1st Try: Openpose log
其實遮是個未果的任務(遮學期垃圾事太多了,特別是某 ML 課程的實驗),並不使我歡喜,但我還是記錄下來,畢竟遮也是成長路上的一次嘗試。
今年三月去找張老師的時候,他告訴我和孫实驗室有一個正在做的項目,是做多路動作的捕捉。簡單說就是一个有多個畫面的視頻,要實時地去捕捉畫面中人的動作。張老師告訴我們現已有一個開源項目 openpose,其較好實現了多人識別,於是想將 openpose 應用到該項目中,但發現在單畫面的時候效果不錯,但多畫面時識別時間就增加以致於達不到實時的效果,而我們的主要任務即是分析此原因。
在後半個學期,參加了四次工作匯报的組會。
1. Read the paper
主要是閱讀了論文 OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,知道實現 openpose 的主要算法,使用自下而上的方法,識別流程,关键技术,如 Part Affinity Fields(PAF) 和 Confidence Maps。
孫看了篇關於 GPU 虚擬化加速 openpose 識別的論文。 張老師說可以先不搞理論優化的,先把 openpose 跑起來。
2. Run the project
於是我們開始研究如何 run 這個 openpose,由於没有提供服務器,最好的方法就是使用免費的 colab 了。我根据網上的一個 notebook run 了一下,孫說跑太慢,决定用智星云的高性能服务器,結果失敗了。(因為我没和他一起配我不太懂,據說是 boost 的版本和 Nvidia cuda 版本對不上,問了焦学姐也没辦法解决,她是在 windows 下配的环境,在 Linux 下就是問題很多…)
那就用 colab 跑吧,我用 python 的 opencv 逐幀拼圖,試了 $3\times 3$ 的带脸部和不带脸部的識別,結果發現不带脸的情況下 $3\times 3$ 的識別時間為 $1\times 1$ 的 $3$ 倍。
學長說可能是圖中祗有三個人,openpose 識別了遮三人,故祗做三次,我覺得不是,因為遮和他論文中提到的自底向上法相悖。
於是下個任务就是分析原因。
3. Analyse the reason
没辦法,上次样本用太少,能得出正确結論才有問题。仔细想下可以發現拼圖的方式很有問題,我是單純把每幀拼在一块,那麼遮樣就無有做到控制變量,因為分辨率提高了。下圖便是佐證。
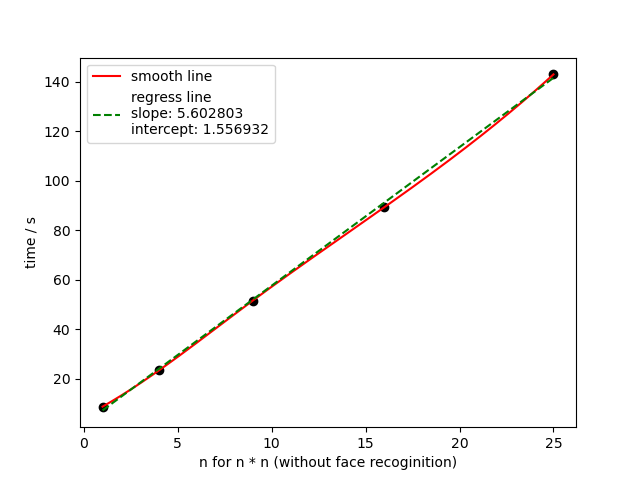
但是遮樣一來便發現此方法關於像素点個數似乎是線性的,於是若控制分辨率那麼多人識別理論要和單人的時間差不多。
4. Optimize ?
但事實不是那麼簡單。在此次,我們主要針對降幀和降分辨率進行優化。
在降幀時出現了異常的波動,具體元因不明,懷疑是其本身有用一些時間序列预測的方式來處理視頻而不是單純一幀一幀地做。
在 issue 中有人提到了關於視頻處理的問题,但並無人解答。
在降分辨率方面可以發現确實時間會差不多但代價仍會隨著畫面數量增多而增大。(並且當畫面中人太多會出錯,此處我們又回去看了下論文,具體得到的結論記不清了)
時間有些久有些細節記不太清了,所以就隨意地記錄下好了。所以我似乎無有結論?